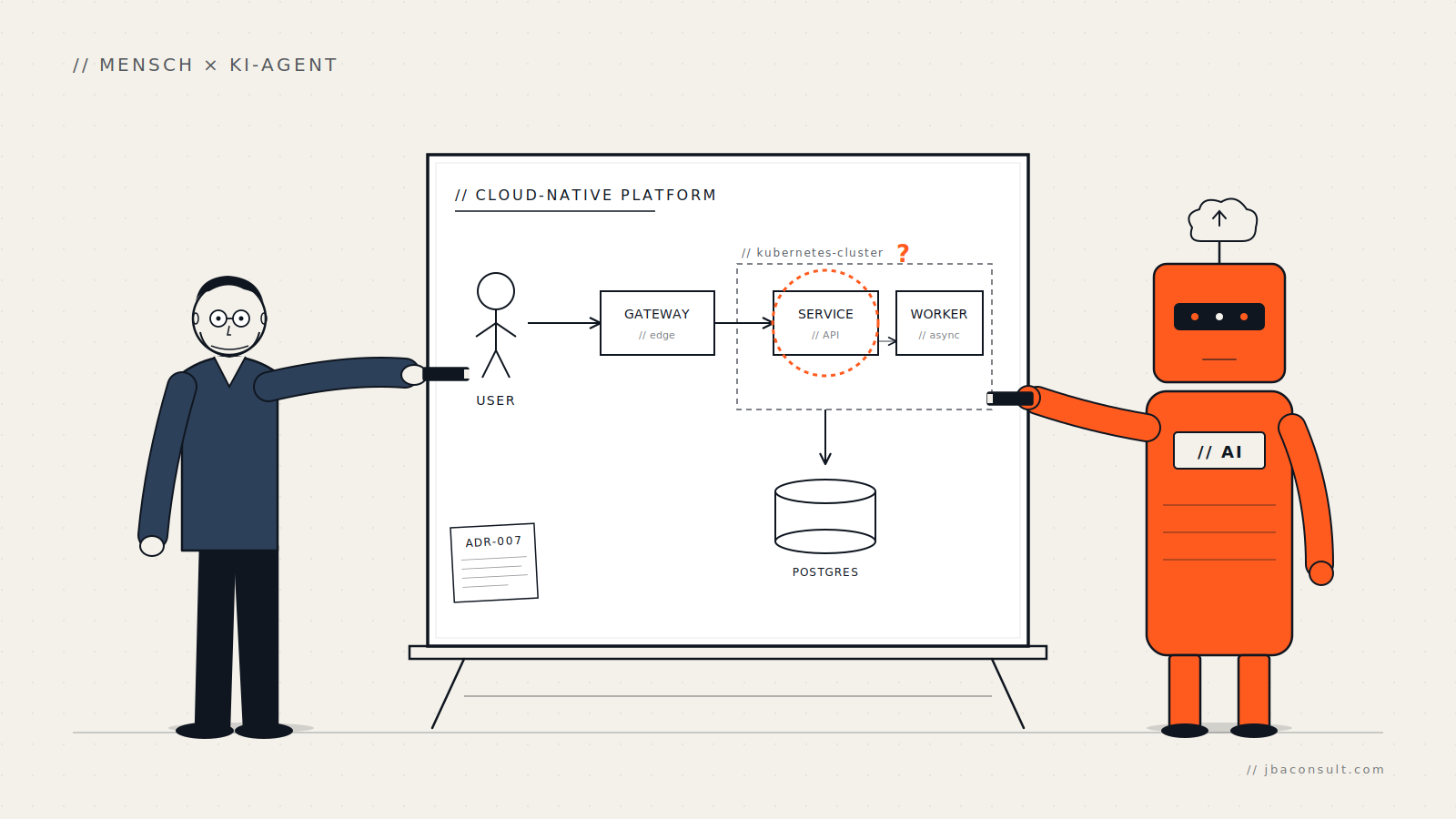
Coding-Agents wie Claude Code oder Cursor verändern den Architektur-Alltag — aber nicht da, wo man es zuerst denkt. Methodisch bleibt fast alles, wie es war: ADRs, Arc42, Reviews, Architektur-Boards. Was sich verschiebt, ist die Distanz zwischen Skizze und Spike — und damit die Frage, womit Architekten ihre Zeit verbringen.
Hook
Vor zwei Wochen saß ich in einem Architektur-Workshop zu einer Microservice-Schnitt-Frage. Drei Schnitt-Varianten standen an der Tafel — der gewohnte Folge-Schritt wäre gewesen: 200 Folien, drei Wochen Architektur-Board-Diskussion, ein Beschluss. Diesmal haben wir die drei Varianten in 90 Minuten als lauffähige Stubs gebaut und gegen ein Test-Szenario geschickt. Der Coding-Agent hat geschrieben, ich habe entschieden, was reingeht.
Das ist die Verschiebung, um die es in diesem Beitrag geht. Nicht die übliche „KI ersetzt Architekten“-Debatte — die ist langweilig und falsch. Sondern: was sich konkret im Alltag ändert, wenn ein Architekt mit Coding-Agents arbeitet — und was eben nicht. Es ist auch der erste Beitrag in einer neuen Säule hier — KI im Architektur-Alltag. Praxis statt Hype, und keine Heils-Versprechen.
Was ein Architektur-Agent nicht ist
Vor den Patterns ein paar Klärungen, weil die Tool-Versprechen oft größer sind als die Realität.
Coding-Agents sind keine Domain-Experten. Sie kennen die Fachsprache deiner Bank, deiner Behörde, deines Energieversorgers nicht. Die Ubiquitous Language muss weiter durch Domain-Workshops und Stakeholder-Gespräche entstehen. Denn kein Agent destilliert dir aus generischem Wissen, was im Antragsverfahren einer Sozialbehörde „Bewilligung“ eigentlich bedeutet.
Sie sind keine Stakeholder-Manager. Wer Architektur betreibt, verbringt grob 60 Prozent der Zeit mit Menschen — Koordinieren, Verhandeln, Übersetzen zwischen Fach und Technik. Davon nehmen Agents nichts ab. Sie helfen beim Aufschreiben, was ihr besprochen habt — nicht beim Aushandeln.
Sie sind keine ADR-Generator-Maschinen. Ein gutes ADR lebt von der Begründung — vom „Warum jetzt, warum nicht das andere“. Diese Begründung kommt aus der Diskussion mit dem Team, nicht aus einem Generator-Prompt. Mehr dazu in Pattern 2.
Und sie sind nicht autonom. „Agentisch“ heißt nicht „arbeitet allein“. Es heißt: kann mehrere Schritte zwischen Architekt-Eingaben planen — etwa eine Datei lesen, einen Test schreiben, ihn ausführen, das Ergebnis interpretieren. Die Eingaben bleiben kritisch. Wer keine guten Eingaben formulieren kann, bekommt schlechte Outputs zurück.
Drei Patterns, die in meinem Alltag funktionieren
Pattern 1 — Spike-Validierung statt Folien-Hypothesen
Klassischer Architektur-Alltag: drei Microservice-Schnitt-Varianten an der Tafel, jede mit ihren Vor- und Nachteilen. Üblicher Pfad — die Varianten als Folien aufbereiten, im Architektur-Board diskutieren, eine wählen. Nach drei Wochen weiß man oft erst, dass die gewählte nicht trägt.
Mit einem Coding-Agent geht der Pfad anders. Statt zu argumentieren, baust du in einem Tag drei lauffähige Stubs — je 200 bis 400 Zeilen, mit echtem Datenmodell, einem groben Persistenz-Layer, einem Test-Szenario, das die kritische Operation durchspielt. Der Agent schreibt 80 Prozent davon, du entscheidest, was rein gehört.
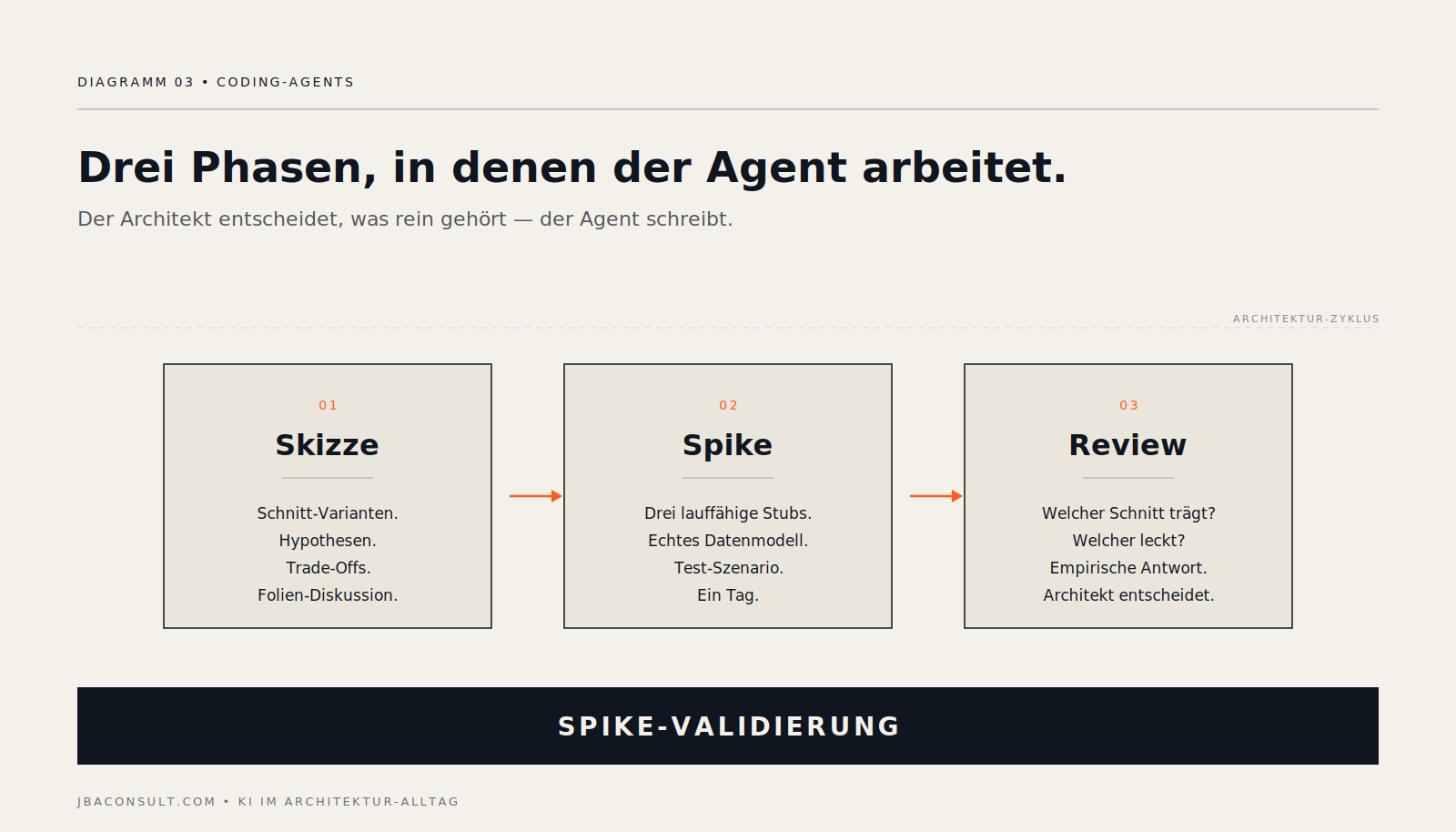
Das macht Schnitt-Varianten vergleichbar, die auf der Folie austauschbar wirken. Erst im Spike sieht man, dass eine Variante beim ersten parallelen Use-Case anfängt zu lecken — weil zwei Bounded Contexts dasselbe Aggregat teilen, oder weil eine versteckte Daten-Abhängigkeit erst im Code sichtbar wird. In der Folien-Diskussion verschwindet sowas hinter Architektur-Schönheits-Argumenten. Drei Stubs gegen ein gemeinsames Test-Szenario zeigen es in einem Tag.
Was du dafür brauchst: ein Test-Szenario, das die Kern-Operation durchspielt. Ohne das ist der Spike beliebig — der Agent baut, was du fragst, aber ohne Akzeptanz-Kriterium hat der Stub keinen Härtetest.
Pattern 2 — ADR-Draft mit Architekt als Reviewer
Früher habe ich ADR-Erstfassungen selbst geschrieben — Optionen sammeln, Trade-Offs aufschreiben, Empfehlung formulieren. Heute gebe ich dem Agent den Kontext: Optionen, betroffene Komponenten, NFRs, was wir im Workshop entschieden haben, was offen blieb. Er liefert den Draft, ich review.
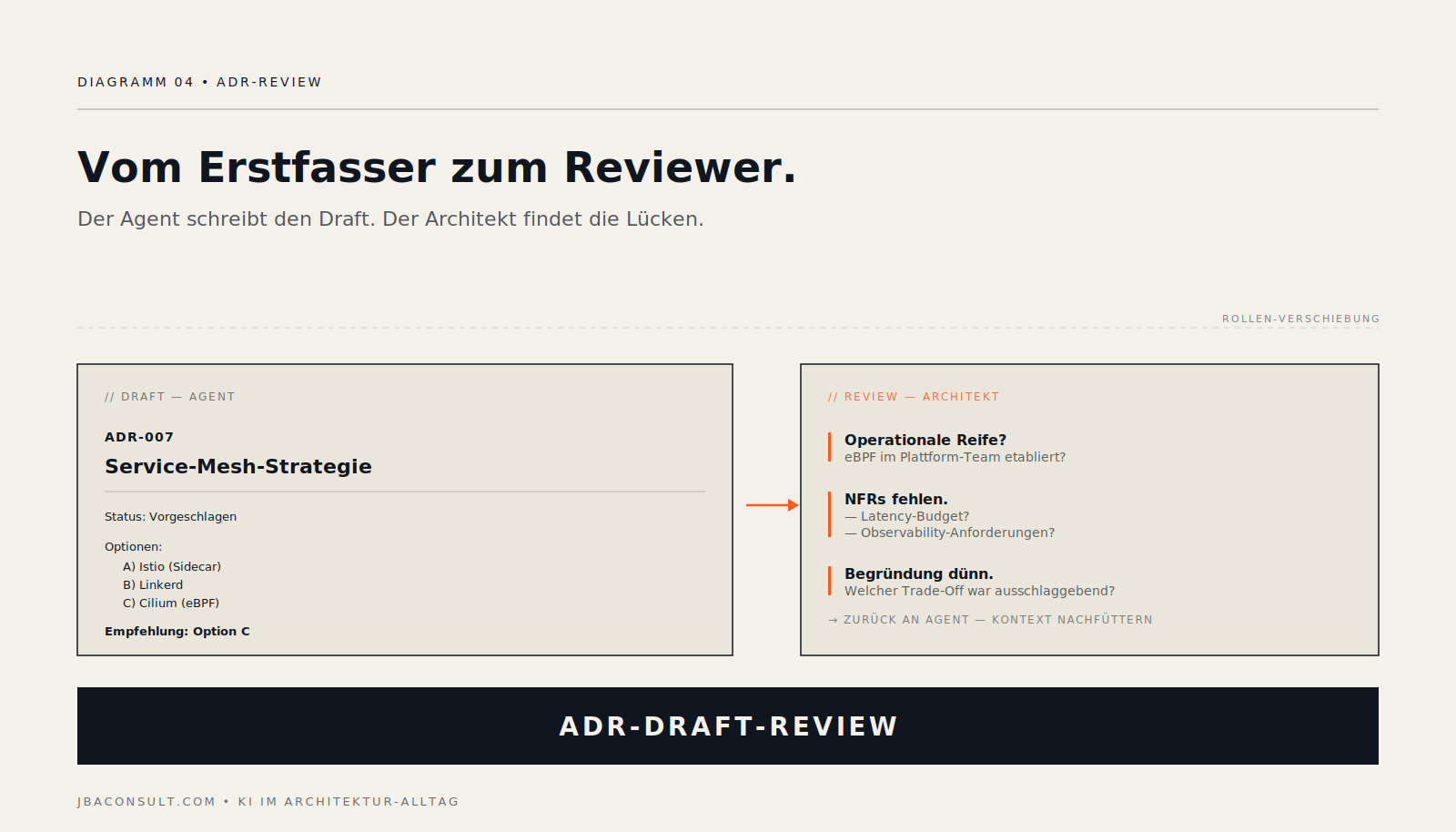
Was sich dabei ändert, ist nicht die Geschwindigkeit. Es ist meine Rolle. Im Schreiben ist man im Argumentations-Strom — beim Reviewen sieht man Lücken klarer. Ich finde im fremden Draft Argumente, die mir beim eigenen Schreiben durchgegangen wären.
Der Agent schreibt nie den letzten Stand. Der Review-Pass durch mich und das Team bleibt — der Draft ist nur ein besseres Whiteboard. Was sich ändert: ich starte den Review-Schritt schon nach 30 Sekunden statt nach zwei Stunden Schreibakt. Mehr zur ADR-Governance in der Praxis im Bereich Architektur-Assessments.
Pattern 3 — Code-Review-Vorprüfung gegen die Architektur-Vorgaben
Vor dem menschlichen Code-Review läuft eine Agent-Vorprüfung gegen den Architektur-Schnitt. Sind die Datenmodell-Boundaries sauber? Kreuzt ein Import die Layer-Grenze, die im ADR festgehalten ist? Hat ein Service in einer Datei, die zur Domain gehört, plötzlich JDBC-Code?
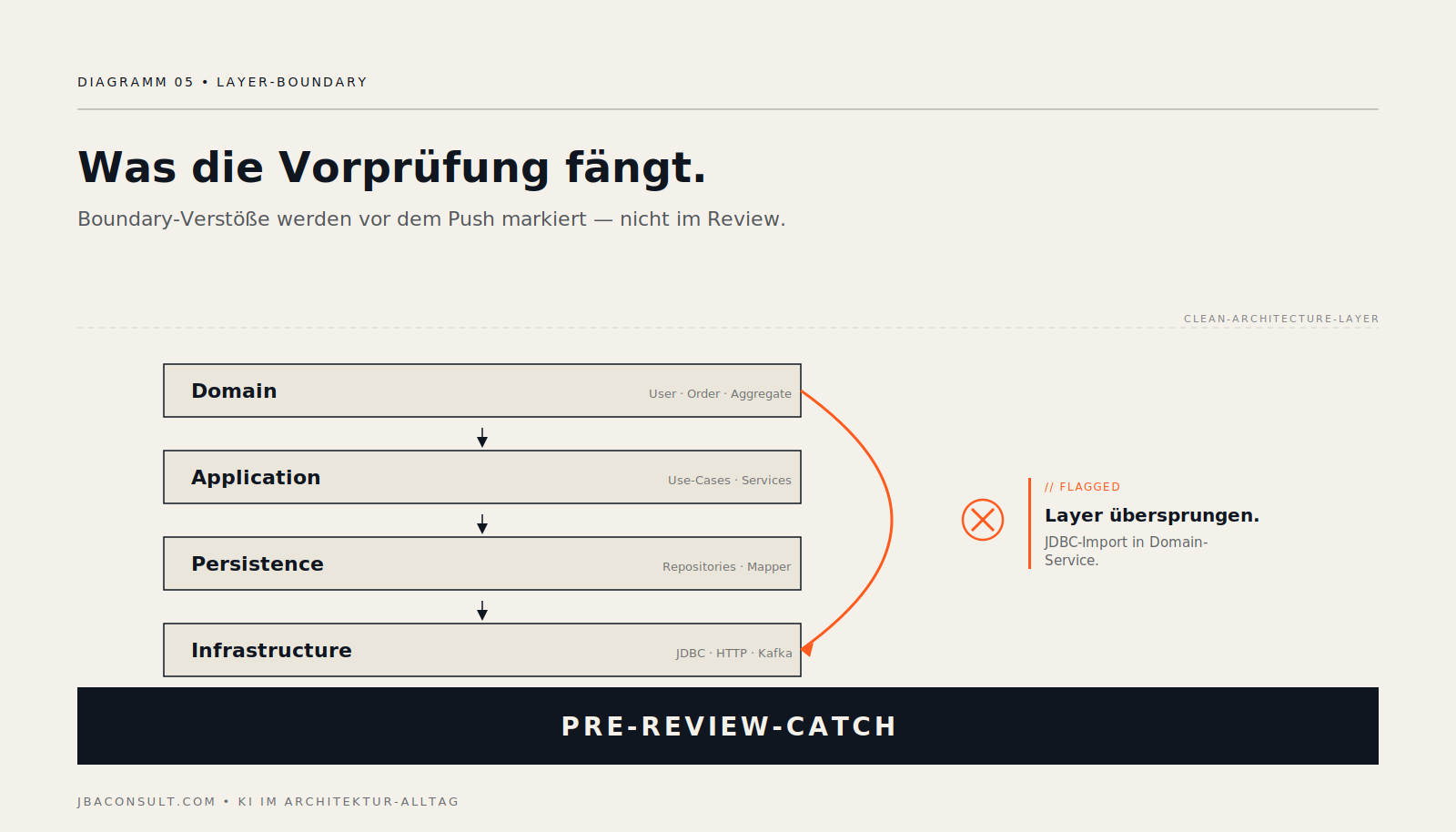
Damit kommt ins menschliche Review nur noch, was substanzielle Diskussion braucht. Nicht der zehnte „der Import läuft an der Layer-Grenze vorbei“ — der ist schon vor dem Push gefangen. Das menschliche Review wird wieder zu dem, wofür es gedacht war: über Schnitt-Fragen reden, nicht über Lint-Fehler.
Wo Agents heute noch versagen
Vier Stellen, an denen ich konsequent zur Hand-Arbeit zurückkehre.
Cross-Service-Migrationen. Wenn ein Schnitt zwischen drei Bounded Contexts mit DB-Migration, Messaging-Topology und Service-Discovery zusammenspielt, verliert der Agent den Faden. Eine sequenzielle Aufgabe lässt sich noch beauftragen. Eine, die parallel über drei Repositories und ein Datenmodell-Refactoring läuft, nicht. Das bleibt Architekt-geführte Schritt-für-Schritt-Arbeit.
NFR-Trade-Offs. „Wir wollen 2-Sekunden-Latenz und 99,95 Prozent Verfügbarkeit, aber das Hardware-Budget ist halb so groß wie nötig“ — das ist kein Code-Problem. Es ist ein Stakeholder-Problem mit Code-Konsequenzen. Agents helfen beim Aufschreiben des Trade-Offs, sie helfen nicht beim Aushandeln. Die Antwort kommt aus dem Gespräch, nicht aus dem Modell.
Domain-spezifische Akzeptanzkriterien. Was im Behördenkontext „compliant“ heißt, weiß der Agent nicht. BSI-Grundschutz-Anforderungen, NIST-Zero-Trust-Linien, branchenspezifische Auditpunkte — das bleibt Mandats-Wissen. Du kannst dem Agent sagen, er soll gegen einen bestimmten Compliance-Katalog prüfen, aber den Katalog musst du mitbringen.
Architektur-Politik. Wenn drei Plattform-Teams unterschiedliche Sicht auf die richtige Service-Mesh-Strategie haben, ist die Antwort nicht im Code zu finden. Der Agent kann Material aufbereiten — Vor- und Nachteile auflisten, Risiken sortieren, Fragen stellen. Die Diskussion bleibt menschlich, weil die Konflikte menschlich sind. Wer das Thema in einer souveränen Cloud-Plattform kennt, weiß, wovon ich spreche — siehe „Souveräne Cloud: Bevor sie landet, steht die Landing Zone“.
Was sich am Architekten-Profil verschiebt
Daraus folgen ein paar Linien für das Selbstverständnis.
Mehr Reviewer-Mentalität, weniger Schreiber-Mentalität. Wer früher 40 Prozent der Zeit mit Skizzen und Erstfassungen verbracht hat, verbringt sie jetzt mit Lesen, Bewerten, Entscheiden. Das ist eine andere Disziplin. Nicht jeder Architekt ist in beiden gleich gut — manchmal ist die Reviewer-Rolle das angenehmere Selbst, manchmal die schwierigere.
Stakeholder-Arbeit gewinnt anteilig. Was Agents nicht abnehmen, wird relativ wichtiger — Zielbild aushandeln, zwischen Fach und Technik übersetzen, Teams coachen. Das ist gut, weil dort der größte Hebel sitzt. Und ehrlich: das war es vorher auch schon, nur war Schreibarbeit ein bequemes Refugium, wenn die Stakeholder-Termine zermürbend wurden.
Höherer Anspruch an die Begründung. Wenn der Agent in 30 Sekunden vier ADR-Optionen produziert, wird die Frage „warum diese und nicht die andere“ akuter. Wer früher mit „aus Erfahrung“ durchkam, wird in Reviews schärfer befragt. Anstrengend, aber für die Qualität der Architektur gut.
Werkzeug-Ehrlichkeit. Wer mit Coding-Agents arbeitet, sollte das im Team transparent machen. Die Behauptung, alles selbst geschrieben zu haben, hält bei aufmerksamen Kollegen ohnehin nicht — und ist nicht der Punkt. Die Verantwortung für den Schnitt liegt weiter beim Architekten. Das Werkzeug ist Werkzeug.
Coding-Agents nehmen das Schreiben ab, nicht das Entscheiden. Und Entscheiden war ohnehin der Architektur-Kern.
Zusammengefasst
- Coding-Agents nehmen das Schreiben ab, nicht das Entscheiden — und Entscheiden war ohnehin der Architektur-Kern.
- Spike-Validierung in einem Tag schlägt Folien-Diskussion in zwei Wochen, sobald die Frage technisch beantwortbar ist.
- ADRs werden besser, wenn der Architekt vom Erstfasser zum Reviewer wird.
- Cross-Service-Migrationen, NFR-Trade-Offs, Domain-Compliance und Architektur-Politik bleiben menschliche Arbeit.
- Wer Coding-Agents einsetzt, sollte es im Team transparent machen — verschiebt nichts an der Verantwortung, klärt Erwartungen.
Wenn du in deinem Architektur-Alltag mit Coding-Agents experimentierst und einen Sparringspartner suchst, schreib mir. → /kontakt/